




Notebooks

Categories



Cells
Premium

BioTuring
Power analyses are considered important factors in designing high-quality experiments. However, such analyses remain a challenge in single-cell RNA-seq studies due to the presence of hierarchical structure within the data (Zimmerman et al., 2021). As cells sampled from the same individual share genetic and environmental backgrounds, these cells are more correlated than cells sampled from different individuals. Currently, most power analyses and hypothesis tests (e.g., differential expression) in scRNA-seq data treat cells as if they were independent, thus ignoring the intra-sample correlation, which could lead to incorrect inferences.
Hierarchicell (Zimmerman, K.D. and Langefeld, C.D., 2021) is an R package proposed to estimate power for testing hypotheses of differential expression in scRNA-seq data while considering the hierarchical correlation structure that exists in the data. The method offers four important categories of functions: data loading and cleaning, empirical estimation of distributions, simulating expression data, and computing type 1 error or power.
In this notebook, we will illustrate an example workflow of Hierarchicell. The notebook is inspired by Hierarchicell's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
Advances in multi-omics have led to an explosion of multimodal datasets to address questions from basic biology to translation. While these data provide novel opportunities for discovery, they also pose management and analysis challenges, thus motivating the development of tailored computational solutions. `muon` is a Python framework for multimodal omics.
It introduces multimodal data containers as `MuData` object. The package also provides state of the art methods for multi-omics data integration. `muon` allows the analysis of both unimodal omics and multimodal omics.
BioTuring
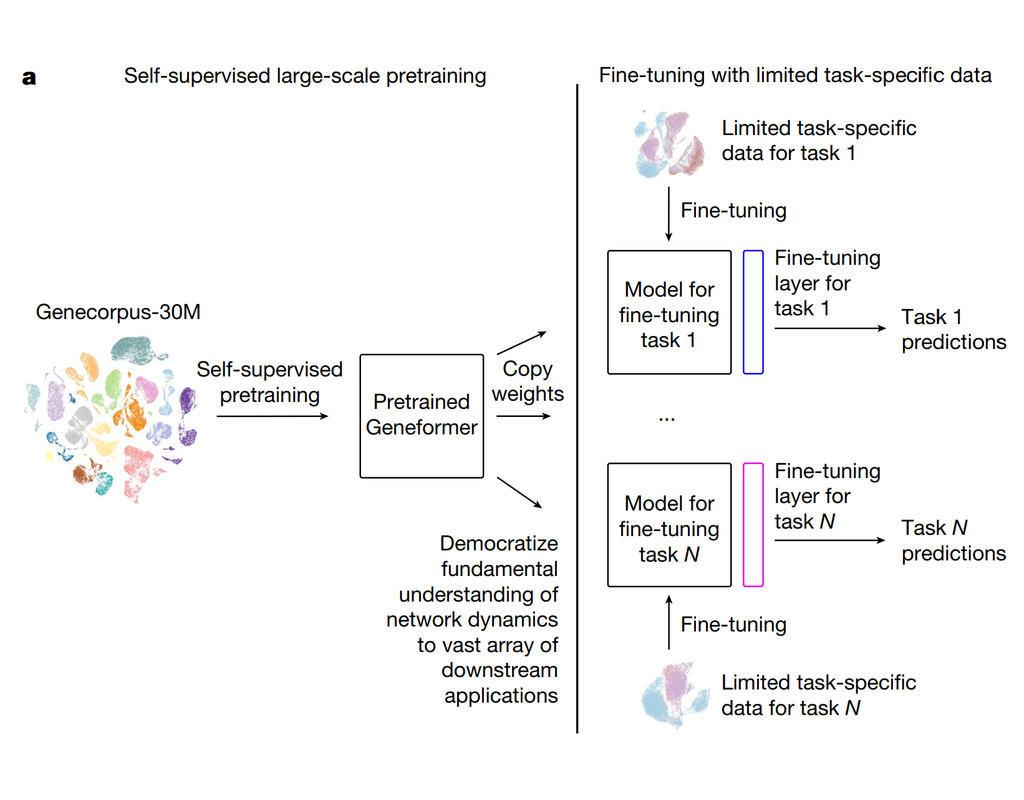
Geneformer is a foundation transformer model pretrained on a large-scale corpus of ~30 million single cell transcriptomes to enable context-aware predictions in settings with limited data in network biology. Here, we will demonstrate a basic workflow to work with ***Geneformer*** models.
These notebooks include the instruction to:
1. Prepare input datasets
2. Finetune Geneformer model to perform specific task
3. Using finetuning models for cell classification and gene classification application

BioTuring
The development of large-scale single-cell atlases has allowed describing cell states in a more detailed manner. Meanwhile, current deep leanring methods enable rapid analysis of newly generated query datasets by mapping them into reference atlases.
expiMap (‘explainable programmable mapper’) Lotfollahi, Mohammad, et al. is one of the methods proposed for single-cell reference mapping. Furthermore, it incorporates prior knowledge from gene sets databases or users to analyze query data in the context of known gene programs (GPs).
Trends

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-ce(More)