




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
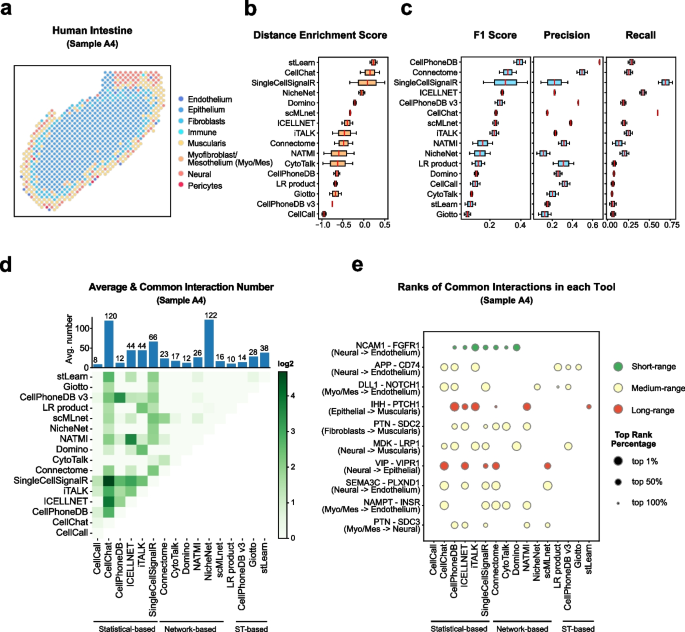
Cell–cell communication mediated by ligand–receptor complexes is critical to coordinating diverse biological processes, such as development, differentiation and inflammation.
To investigate how the context-dependent crosstalk of different cell types enables physiological processes to proceed, we developed CellPhoneDB, a novel repository of ligands, receptors and their interactions. In contrast to other repositories, our database takes into account the subunit architecture of both ligands and receptors, representing heteromeric complexes accurately.
We integrated our resource with a statistical framework that predicts enriched cellular interactions between two cell types from single-cell transcriptomics data. Here, we outline the structure and content of our repository, provide procedures for inferring cell–cell communication networks from single-cell RNA sequencing data and present a practical step-by-step guide to help implement the protocol.
CellPhoneDB v.2.0 is an updated version of our resource that incorporates additional functionalities to enable users to introduce new interacting molecules and reduces the time and resources needed to interrogate large datasets.
CellPhoneDB v.2.0 is publicly available, both as code and as a user-friendly web interface; it can be used by both experts and researchers with little experience in computational genomics.
In our protocol, we demonstrate how to evaluate meaningful biological interactions with CellPhoneDB v.2.0 using published datasets. This protocol typically takes ~2 h to complete, from installation to statistical analysis and visualization, for a dataset of ~10 GB, 10,000 cells and 19 cell types, and using five threads.

BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.
BioTuring
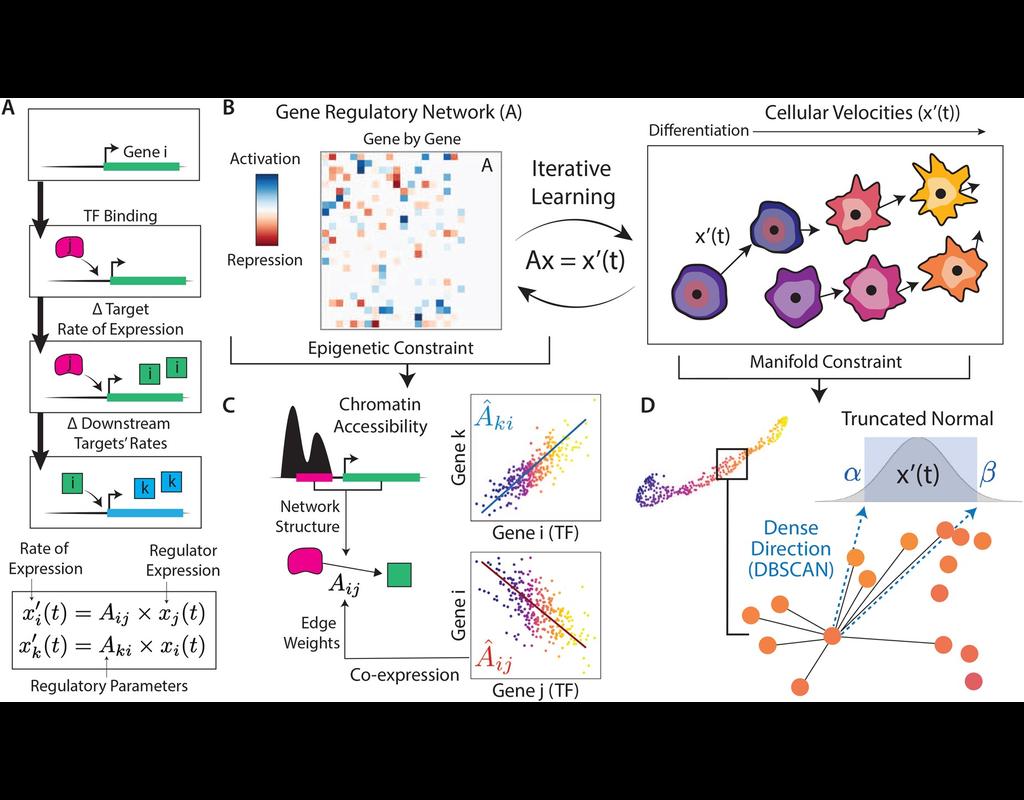
In the realm of transcriptional dynamics, understanding the intricate interplay of regulatory proteins is crucial for deciphering processes ranging from normal development to disease progression. However, traditional RNA velocity methods often overlook the underlying regulatory drivers of gene expression changes over time. This gap in knowledge hinders our ability to unravel the mechanistic intricacies of these dynamic processes.
scKINETICs (Key regulatory Interaction NETwork for Inferring Cell Speed) (Burdziak et al, 2023) offers a dynamic model for gene expression changes that simultaneously learns per-cell transcriptional velocities and a governing gene regulatory network. By employing an expectation-maximization approach, scKINETICS quantifies the impact of each regulatory element on its target genes, incorporating insights from epigenetic data, gene-gene coexpression patterns and constraints dictated by the phenotypic manifold.
BioTuring
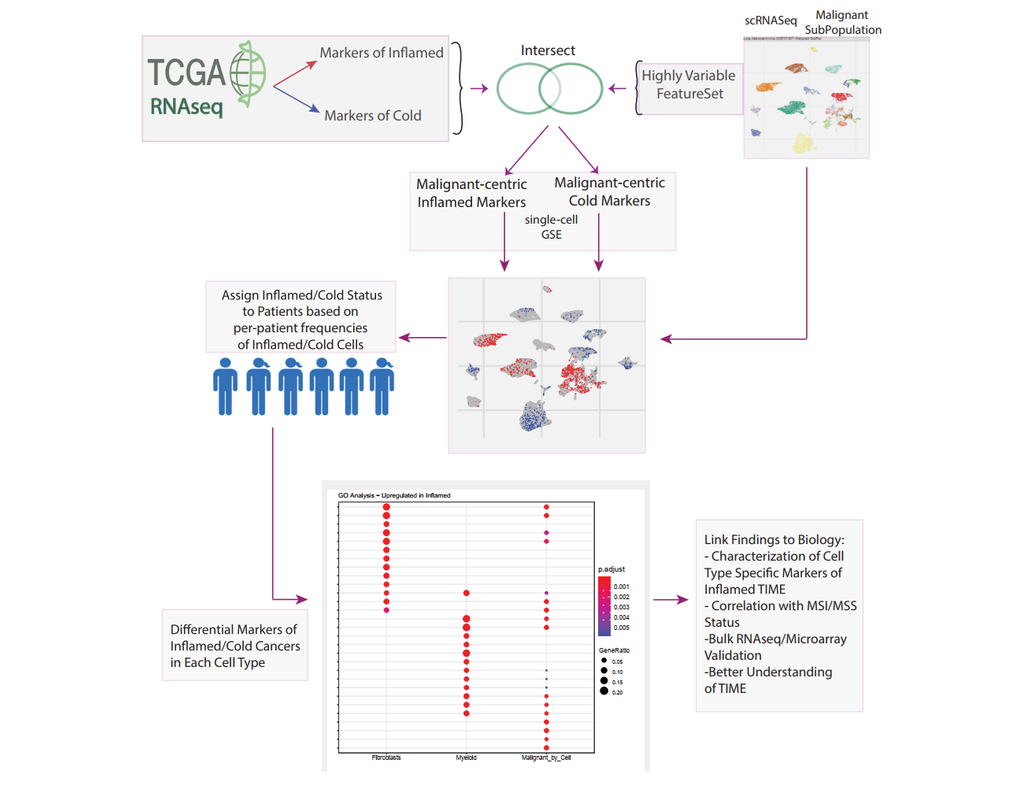
The development of immune checkpoint-based immunotherapies has been a major advancement in the treatment of cancer, with a subset of patients exhibiting durable clinical responses. A predictive biomarker for immunotherapy response is the pre-existing T-cell infiltration in the tumor immune microenvironment (TIME).
Bulk transcriptomics-based approaches can quantify the degree of T-cell infiltration using deconvolution methods and identify additional markers of inflamed/cold cancers at the bulk level. However, bulk techniques are unable to identify biomarkers of individual cell types. Although single-cell RNA sequencing (scRNAseq) assays are now being used to profile the TIME, to our knowledge there is no method of identifying patients with a T-cell inflamed TIME from scRNAseq data. Here, we describe a method, iBRIDGE, which integrates reference bulk RNAseq data with the malignant subset of scRNAseq datasets to identify patients with a T-cell inflamed TIME.
Utilizing two datasets with matched bulk data, we show iBRIDGE results correlated highly with bulk assessments (0.85 and 0.9 correlation coefficients). Using iBRIDGE, we identified markers of inflamed phenotypes in malignant cells, myeloid cells, and fibroblasts, establishing type I and type II interferon pathways as dominant signals, especially in malignant and myeloid cells, and finding the TGFβ-driven mesenchymal phenotype not only in fibroblasts but also in malignant cells.
Besides relative classification, per-patient average iBRIDGE scores and independent RNAScope quantifications were utilized for threshold-based absolute classification. Moreover, iBRIDGE can be applied to in vitro grown cancer cell lines and can identify the cell lines that are adapted from inflamed/cold patient tumors.