




Notebooks

Categories



Cells
Premium

BioTuring
Single-cell RNA data allows cell-cell communications (***CCC***) methods to infer CCC at either the individual cell or cell cluster/cell type level, but physical distances between cells are not preserved Almet, Axel A., et al., (2021). On the other hand, spatial data provides spatial distances between cells, but single-cell or gene resolution is potentially lost. Therefore, integrating two types of data in a proper manner can complement their strengths and limitations, from that improve CCC analysis.
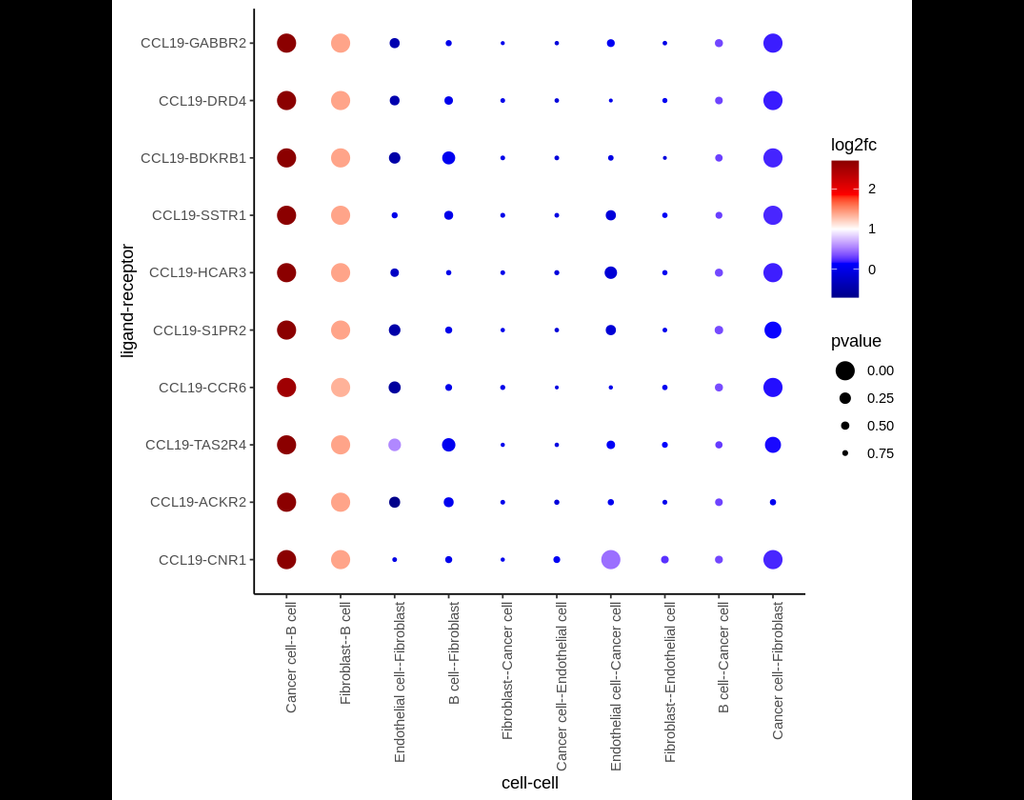
In this pipeline, we analyze CCC on Visium data with single-cell data as a reference. The pipeline includes 4 sub-notebooks as following
01-deconvolution: This step involves deconvolution and cell type annotation for Visium data, with cell type information obtained from a relevant single-cell dataset. The deconvolution method is SpatialDWLS which is integrated in Giotto package.
02-giotto: performs spatial based CCC and expression based CCC on Visium data using Giotto method.
03-nichenet: performs spatial based CCC and expression based CCC on Visium data using NicheNet method.
04-visualization: visualizes CCC results obtained from Giotto and NicheNet.
BioTuring
The development of immune checkpoint-based immunotherapies has been a major advancement in the treatment of cancer, with a subset of patients exhibiting durable clinical responses. A predictive biomarker for immunotherapy response is the pre-existing T-cell infiltration in the tumor immune microenvironment (TIME).
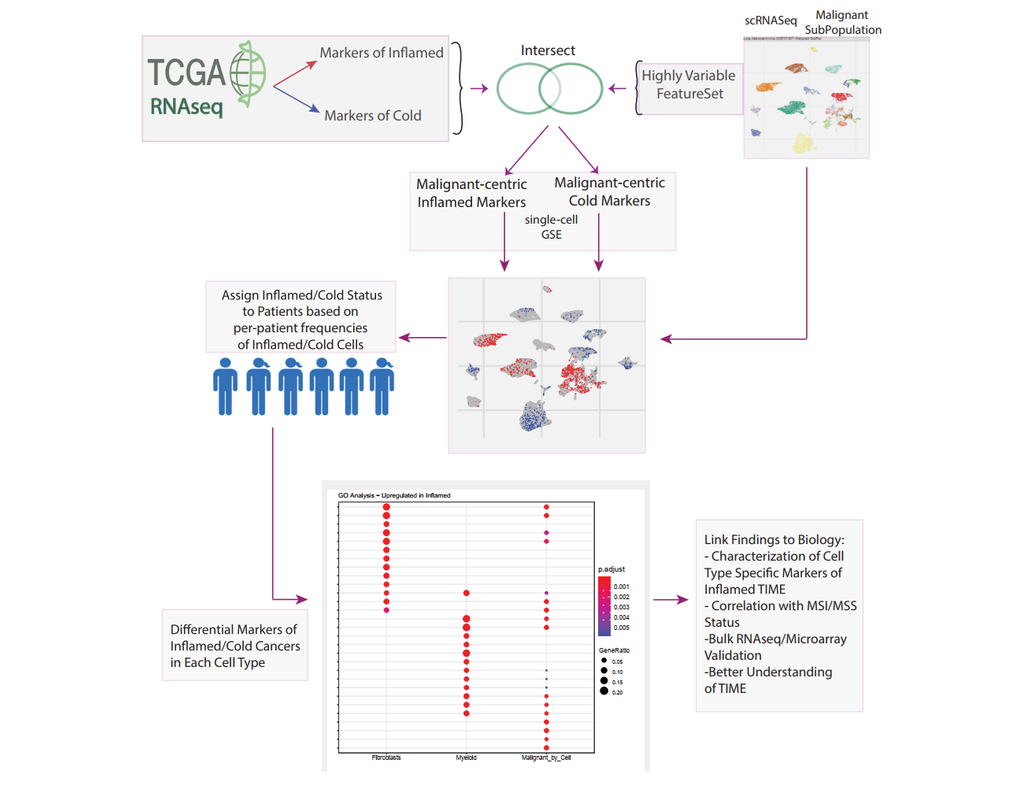
Bulk transcriptomics-based approaches can quantify the degree of T-cell infiltration using deconvolution methods and identify additional markers of inflamed/cold cancers at the bulk level. However, bulk techniques are unable to identify biomarkers of individual cell types. Although single-cell RNA sequencing (scRNAseq) assays are now being used to profile the TIME, to our knowledge there is no method of identifying patients with a T-cell inflamed TIME from scRNAseq data. Here, we describe a method, iBRIDGE, which integrates reference bulk RNAseq data with the malignant subset of scRNAseq datasets to identify patients with a T-cell inflamed TIME.
Utilizing two datasets with matched bulk data, we show iBRIDGE results correlated highly with bulk assessments (0.85 and 0.9 correlation coefficients). Using iBRIDGE, we identified markers of inflamed phenotypes in malignant cells, myeloid cells, and fibroblasts, establishing type I and type II interferon pathways as dominant signals, especially in malignant and myeloid cells, and finding the TGFβ-driven mesenchymal phenotype not only in fibroblasts but also in malignant cells.
Besides relative classification, per-patient average iBRIDGE scores and independent RNAScope quantifications were utilized for threshold-based absolute classification. Moreover, iBRIDGE can be applied to in vitro grown cancer cell lines and can identify the cell lines that are adapted from inflamed/cold patient tumors.
BioTuring
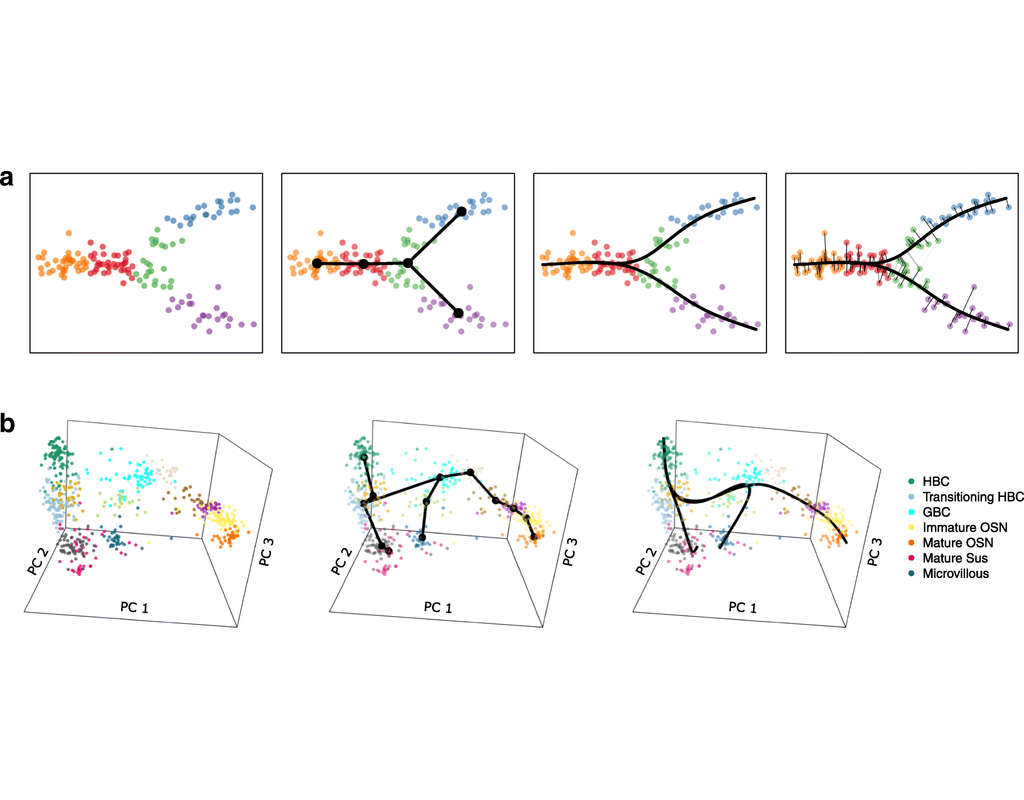
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
Charting an organs’ biological atlas requires us to spatially resolve the entire single-cell transcriptome, and to relate such cellular features to the anatomical scale. Single-cell and single-nucleus RNA-seq (sc/snRNA-seq) can profile cells comprehensively, but lose spatial information.
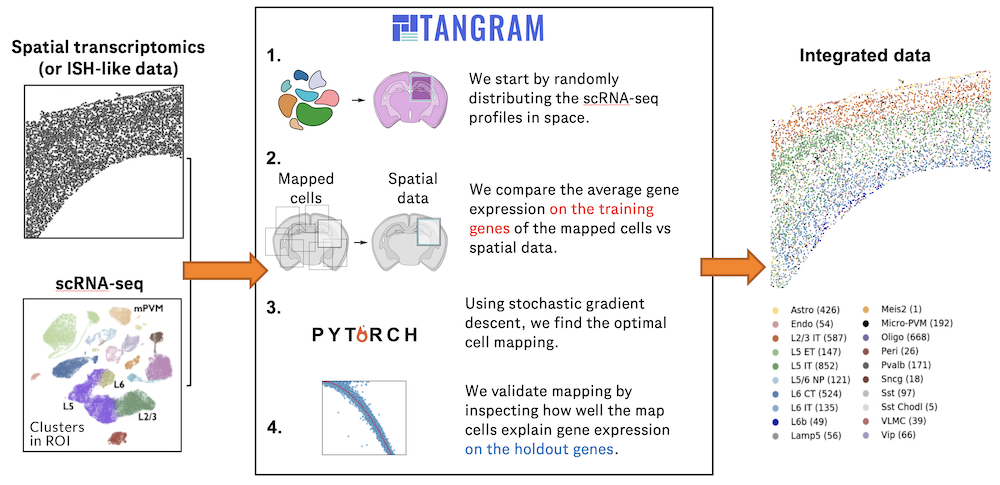
Spatial transcriptomics allows for spatial measurements, but at lower resolution and with limited sensitivity. Targeted in situ technologies solve both issues, but are limited in gene throughput. To overcome these limitations we present Tangram, a method that aligns sc/snRNA-seq data to various forms of spatial data collected from the same region, including MERFISH, STARmap, smFISH, Spatial Transcriptomics (Visium) and histological images.
**Tangram** can map any type of sc/snRNA-seq data, including multimodal data such as those from SHARE-seq, which we used to reveal spatial patterns of chromatin accessibility. We demonstrate Tangram on healthy mouse brain tissue, by reconstructing a genome-wide anatomically integrated spatial map at single-cell resolution of the visual and somatomotor areas.
Trends
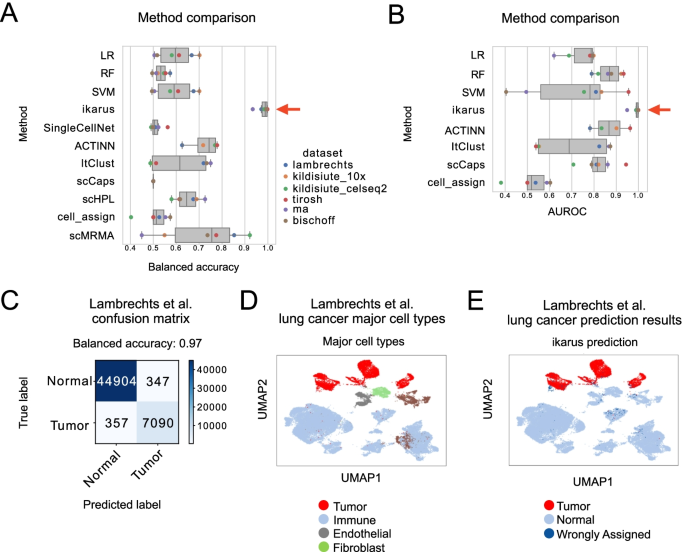
BioTuring
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the(More)
BioTuring
This tool provides a user-friendly and automated way to analyze large-scale single-cell RNA-seq datasets stored in RDS (Seurat) format. It allows users to run various analysis tools on their data in one command, streamlining the analysis workflow and(More)