




Notebooks

Categories



Cells
Premium

BioTuring
Spatial transcriptomics (ST) technology has allowed to capture of topographical gene expression profiling of tumor tissues, but single-cell resolution is potentially lost. Identifying cell identities in ST datasets from tumors or other samples remains challenging for existing cell-type deconvolution methods.
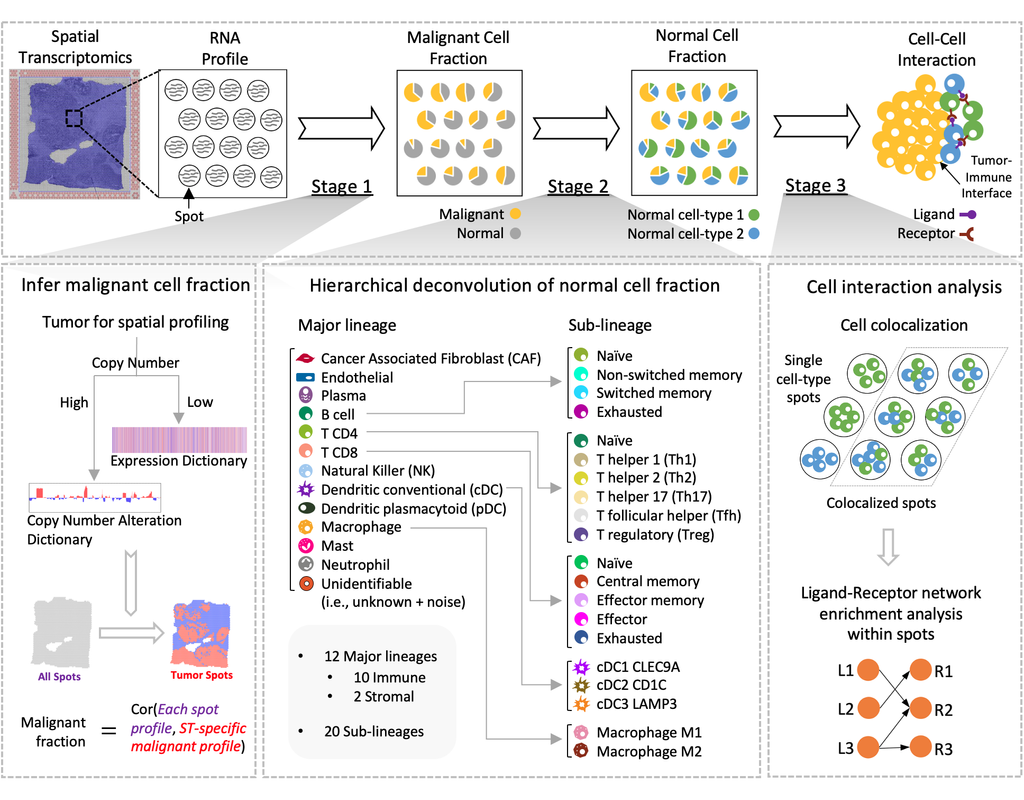
Spatial Cellular Estimator for Tumors (SpaCET) is an R package for analyzing cancer ST datasets to estimate cell lineages and intercellular interactions in the tumor microenvironment. Generally, SpaCET infers the malignant cell fraction through a gene pattern dictionary, then calibrates local cell densities and determines immune and stromal cell lineage fractions using a constrained regression model. Finally, the method can reveal putative cell-cell interactions in the tumor microenvironment.
In this notebook, we will illustrate an example workflow for cell type deconvolution and interaction analysis on breast cancer ST data from 10X Visium. The notebook is inspired by SpaCET's vignettes and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
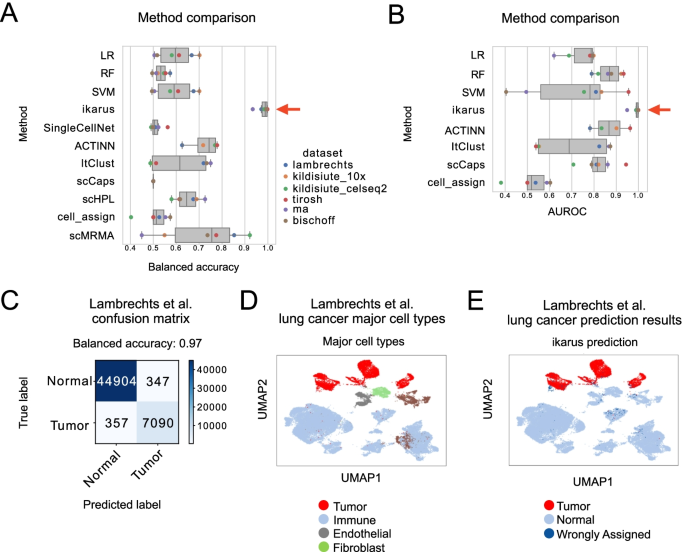
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.
BioTuring
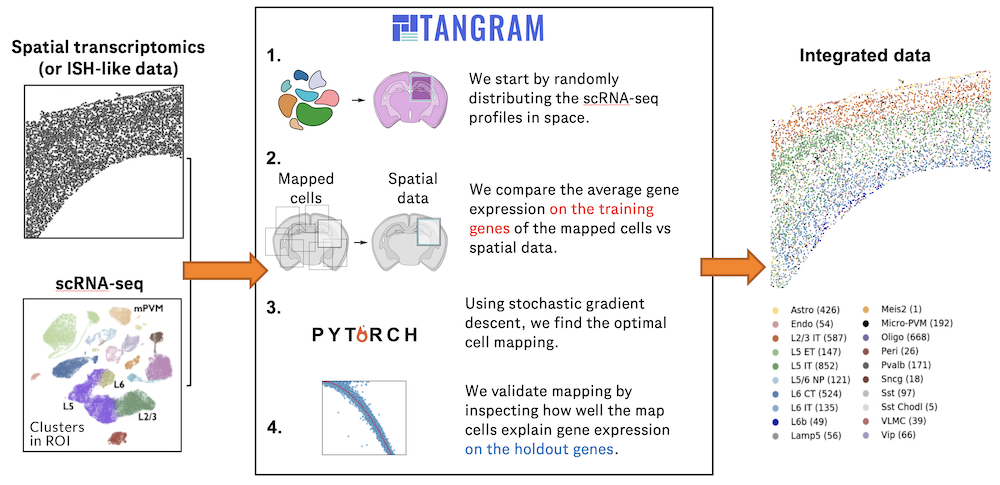
Charting an organs’ biological atlas requires us to spatially resolve the entire single-cell transcriptome, and to relate such cellular features to the anatomical scale. Single-cell and single-nucleus RNA-seq (sc/snRNA-seq) can profile cells comprehensively, but lose spatial information.
Spatial transcriptomics allows for spatial measurements, but at lower resolution and with limited sensitivity. Targeted in situ technologies solve both issues, but are limited in gene throughput. To overcome these limitations we present Tangram, a method that aligns sc/snRNA-seq data to various forms of spatial data collected from the same region, including MERFISH, STARmap, smFISH, Spatial Transcriptomics (Visium) and histological images.
**Tangram** can map any type of sc/snRNA-seq data, including multimodal data such as those from SHARE-seq, which we used to reveal spatial patterns of chromatin accessibility. We demonstrate Tangram on healthy mouse brain tissue, by reconstructing a genome-wide anatomically integrated spatial map at single-cell resolution of the visual and somatomotor areas.
BioTuring
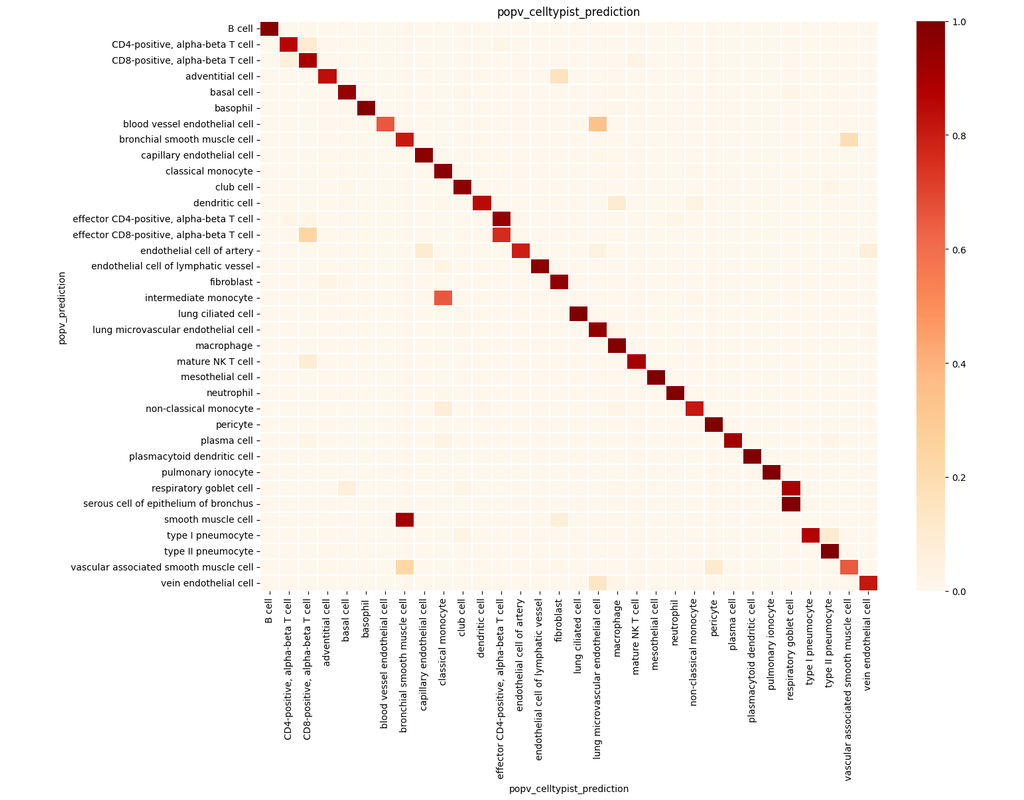
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.
Trends
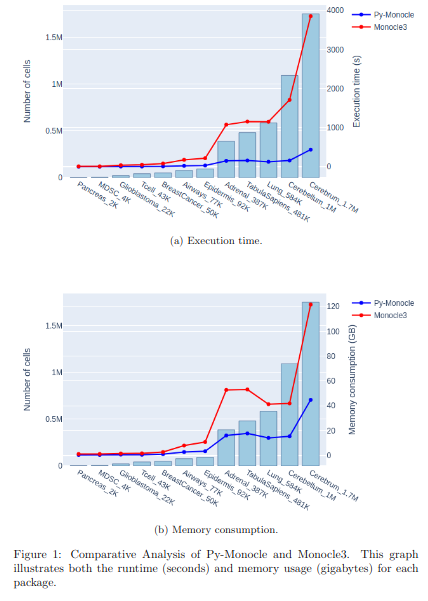
BioTuring
BioTuring Py-Monocle is a package tailored for computing pseudotime on large single-cell datasets. Implemented in Python and drawing inspiration from the Monocle3 package in R, our approach optimizes select steps for enhanced performance efficiency. (More)