




Notebooks

Categories



Cells
Premium

BioTuring
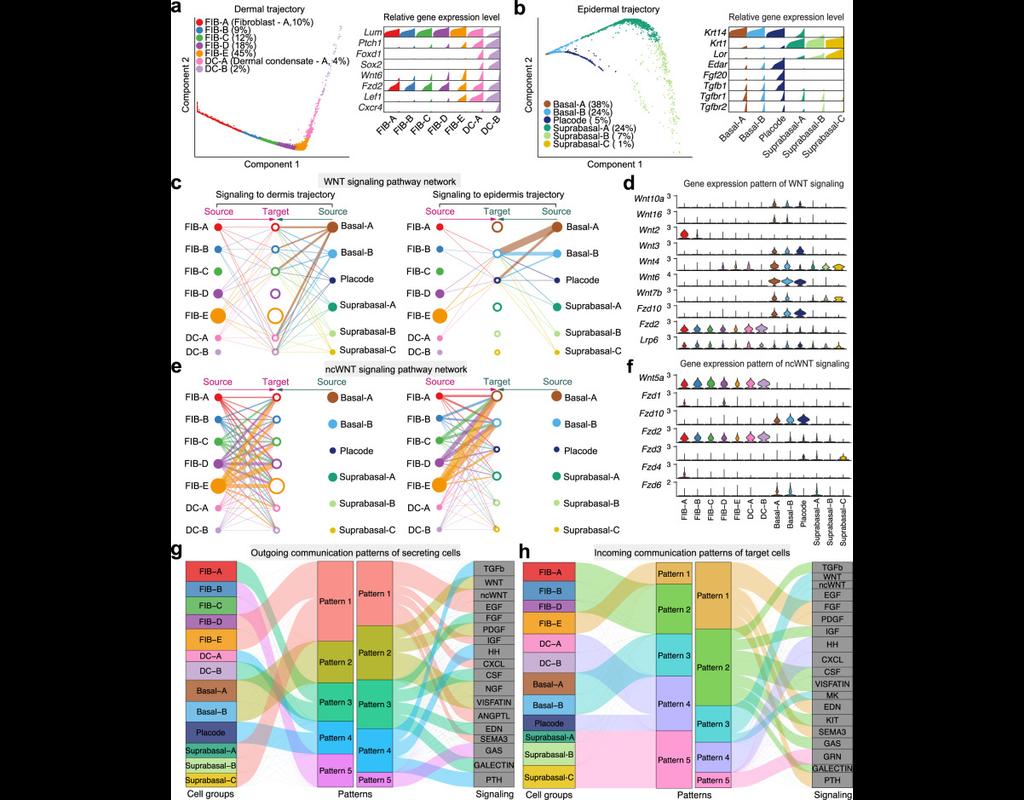
Understanding global communications among cells requires accurate representation of cell-cell signaling links and effective systems-level analyses of those links.
We construct a database of interactions among ligands, receptors and their cofactors that accurately represent known heteromeric molecular complexes. We then develop **CellChat**, a tool that is able to quantitatively infer and analyze intercellular communication networks from single-cell RNA-sequencing (scRNA-seq) data.
CellChat predicts major signaling inputs and outputs for cells and how those cells and signals coordinate for functions using network analysis and pattern recognition approaches. Through manifold learning and quantitative contrasts, CellChat classifies signaling pathways and delineates conserved and context-specific pathways across different datasets.
Applying **CellChat** to mouse and human skin datasets shows its ability to extract complex signaling patterns.
BioTuring
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows statistical strength across locations, thereby enabling the integration of single cell and spatial transcriptomics with higher sensitivity and resolution than existing tools. This is achieved by estimating which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).
This tutorial shows how to use cell2location method for spatially resolving fine-grained cell types by integrating 10X Visium data with scRNA-seq reference of cell types. Cell2location is a principled Bayesian model that estimates which combination of cell types in which cell abundance could have given the mRNA counts in the spatial data, while modelling technical effects (platform/technology effect, contaminating RNA, unexplained variance).

BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.

BioTuring
The development of large-scale single-cell atlases has allowed describing cell states in a more detailed manner. Meanwhile, current deep leanring methods enable rapid analysis of newly generated query datasets by mapping them into reference atlases.
expiMap (‘explainable programmable mapper’) Lotfollahi, Mohammad, et al. is one of the methods proposed for single-cell reference mapping. Furthermore, it incorporates prior knowledge from gene sets databases or users to analyze query data in the context of known gene programs (GPs).
Trends
BioTuring
Power analyses are considered important factors in designing high-quality experiments. However, such analyses remain a challenge in single-cell RNA-seq studies due to the presence of hierarchical structure within the data (Zimmerman et al., 2021). As(More)