




Notebooks

Categories



Cells
Premium

BioTuring
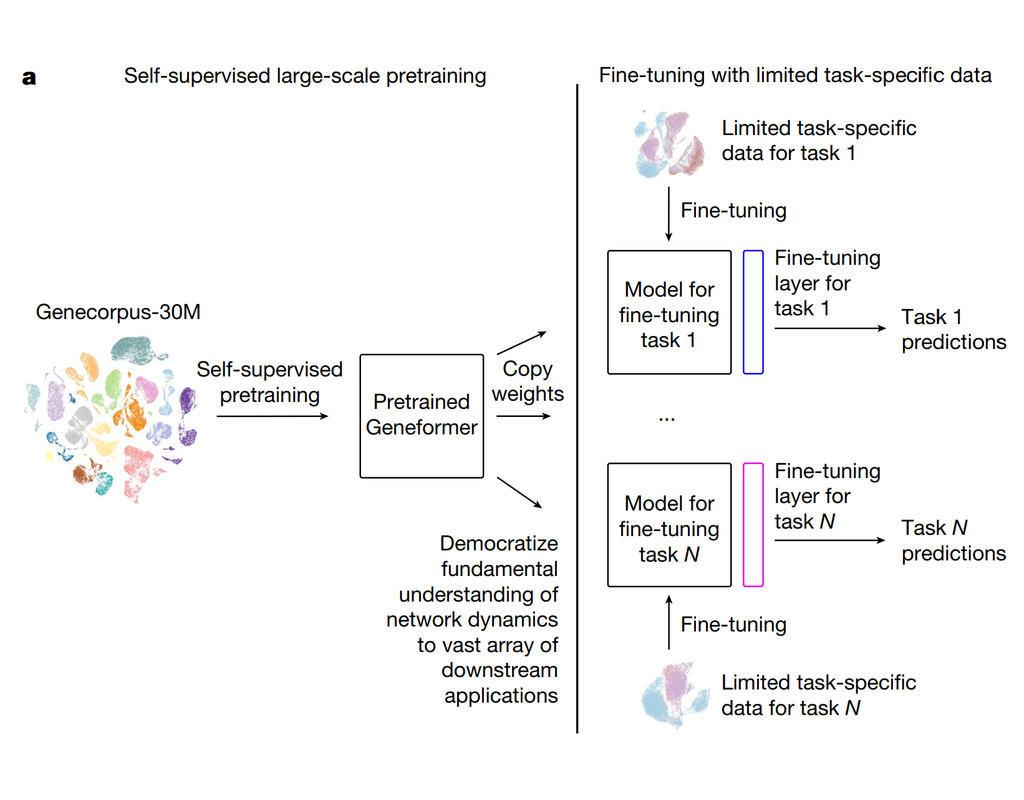
Geneformer is a foundation transformer model pretrained on a large-scale corpus of ~30 million single cell transcriptomes to enable context-aware predictions in settings with limited data in network biology. Here, we will demonstrate a basic workflow to work with ***Geneformer*** models.
These notebooks include the instruction to:
1. Prepare input datasets
2. Finetune Geneformer model to perform specific task
3. Using finetuning models for cell classification and gene classification application
BioTuring
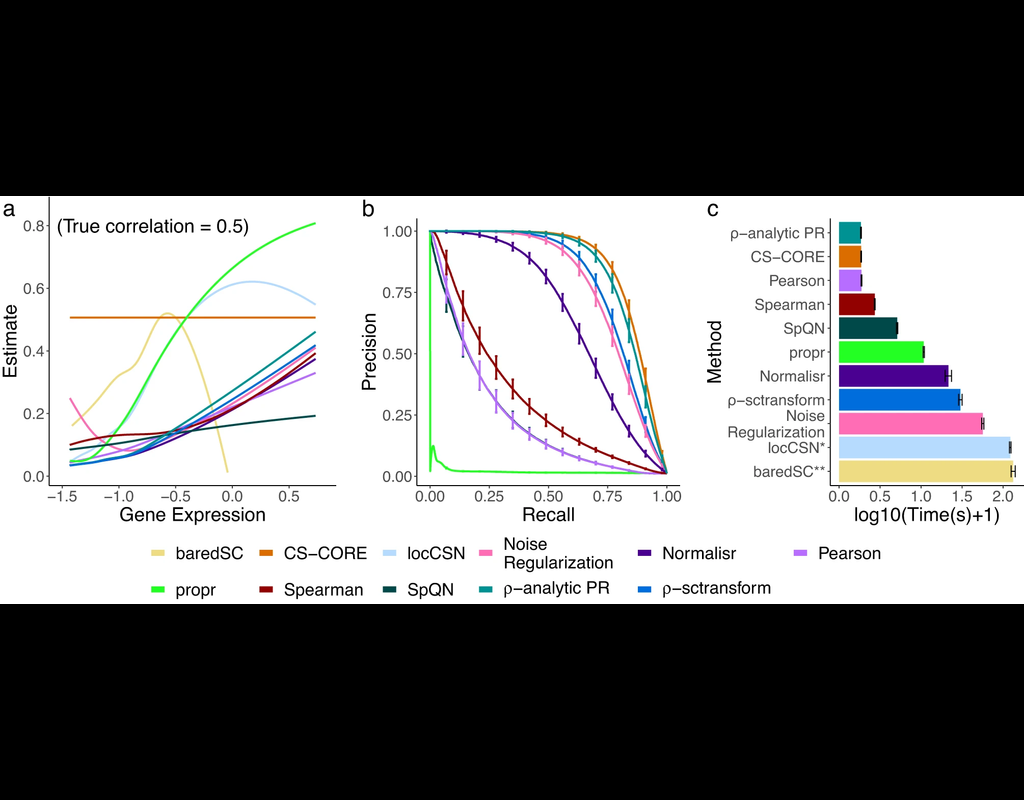
The recent development of single-cell RNA-sequencing (scRNA-seq) technology has enabled us to infer cell-type-specific co-expression networks, enhancing our understanding of cell-type-specific biological functions. However, existing methods proposed for this task still face challenges due to unique characteristics in scRNA-seq data, such as high sequencing depth variations across cells and measurement errors.
CS-CORE (Su, C., Xu, Z., Shan, X. et al., 2023), an R package for cell-type-specific co-expression inference, explicitly models sequencing depth variations and measurement errors in scRNA-seq data.
In this notebook, we will illustrate an example workflow of CS-CORE using a dataset of Peripheral Blood Mononuclear Cells (PBMC) from COVID patients and healthy controls (Wilk et al., 2020). The notebook content is inspired by CS-CORE's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
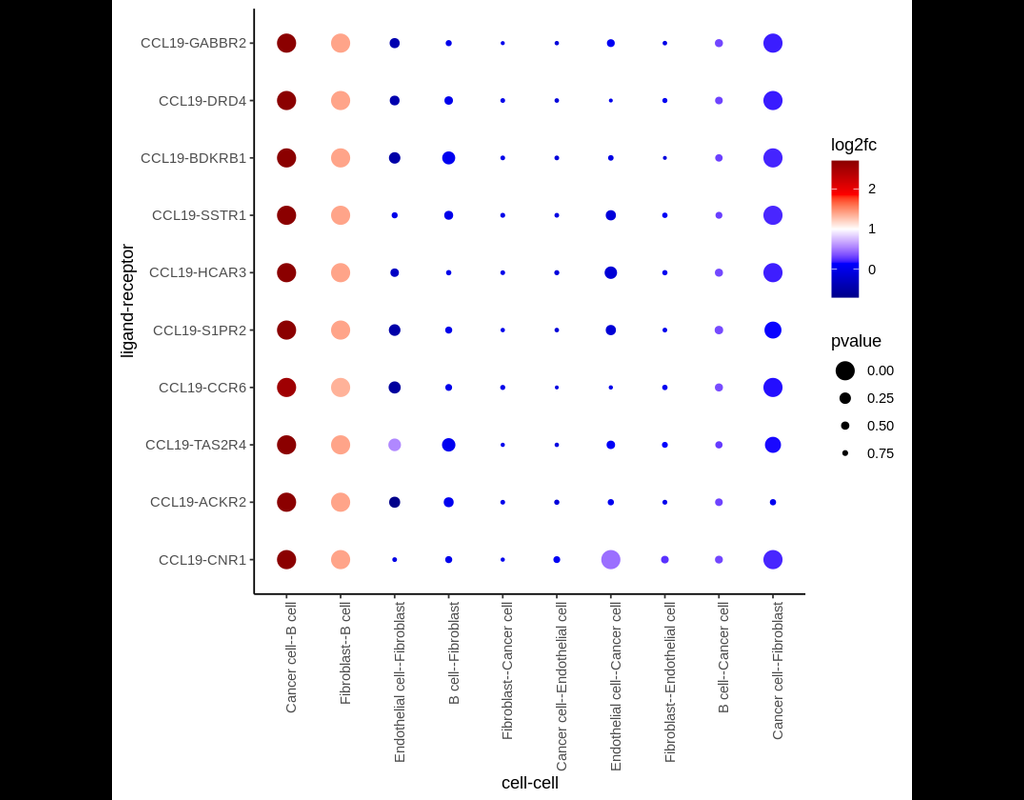
Single-cell RNA data allows cell-cell communications (***CCC***) methods to infer CCC at either the individual cell or cell cluster/cell type level, but physical distances between cells are not preserved Almet, Axel A., et al., (2021). On the other hand, spatial data provides spatial distances between cells, but single-cell or gene resolution is potentially lost. Therefore, integrating two types of data in a proper manner can complement their strengths and limitations, from that improve CCC analysis.
In this pipeline, we analyze CCC on Visium data with single-cell data as a reference. The pipeline includes 4 sub-notebooks as following
01-deconvolution: This step involves deconvolution and cell type annotation for Visium data, with cell type information obtained from a relevant single-cell dataset. The deconvolution method is SpatialDWLS which is integrated in Giotto package.
02-giotto: performs spatial based CCC and expression based CCC on Visium data using Giotto method.
03-nichenet: performs spatial based CCC and expression based CCC on Visium data using NicheNet method.
04-visualization: visualizes CCC results obtained from Giotto and NicheNet.
BioTuring
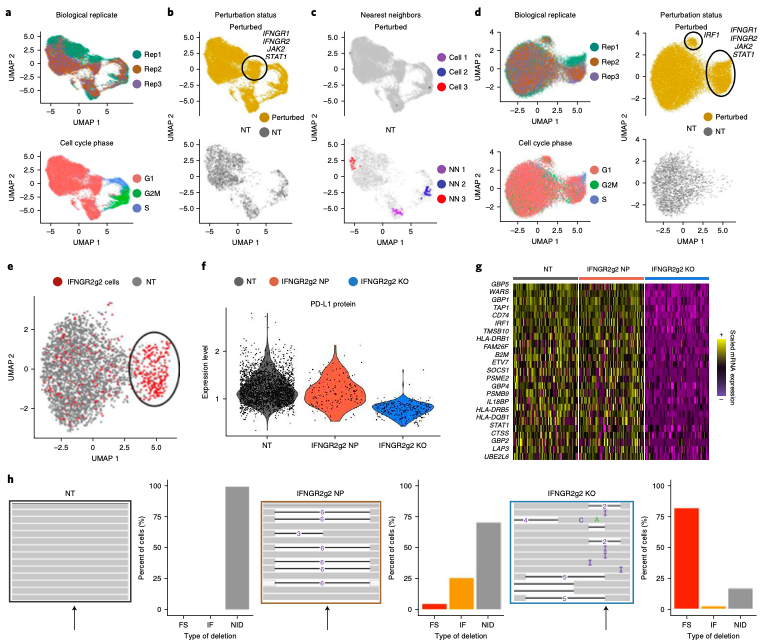
Expanded CRISPR-compatible CITE-seq (ECCITE-seq) which is built upon pooled CRISPR screens, allows to simultaneously measure transcriptomes, surface protein levels, and single-guide RNA (sgRNA) sequences at single-cell resolution. The technique enables multimodal characterization of each perturbation and effect exploration. However, it also encounters heterogeneity and complexity which can cause substantial noise into downstream analyses.
Mixscape (Papalexi, Efthymia, et al., 2021) is a computational framework proposed to substantially improve the signal-to-noise ratio in single-cell perturbation screens by identifying and removing confounding sources of variation.
In this notebooks, we demonstrate Mixscape's features using pertpy - a Python package offering a range of tools for perturbation analysis. The original pipeline of Mixscape implemented in R can be found here.
Trends
BioTuring
Cell2location is a principled Bayesian model that can resolve fine-grained cell types in spatial transcriptomic data and create comprehensive cellular maps of diverse tissues. Cell2location accounts for technical sources of variation and borrows stat(More)