




Notebooks

Categories



Cells
Premium

BioTuring
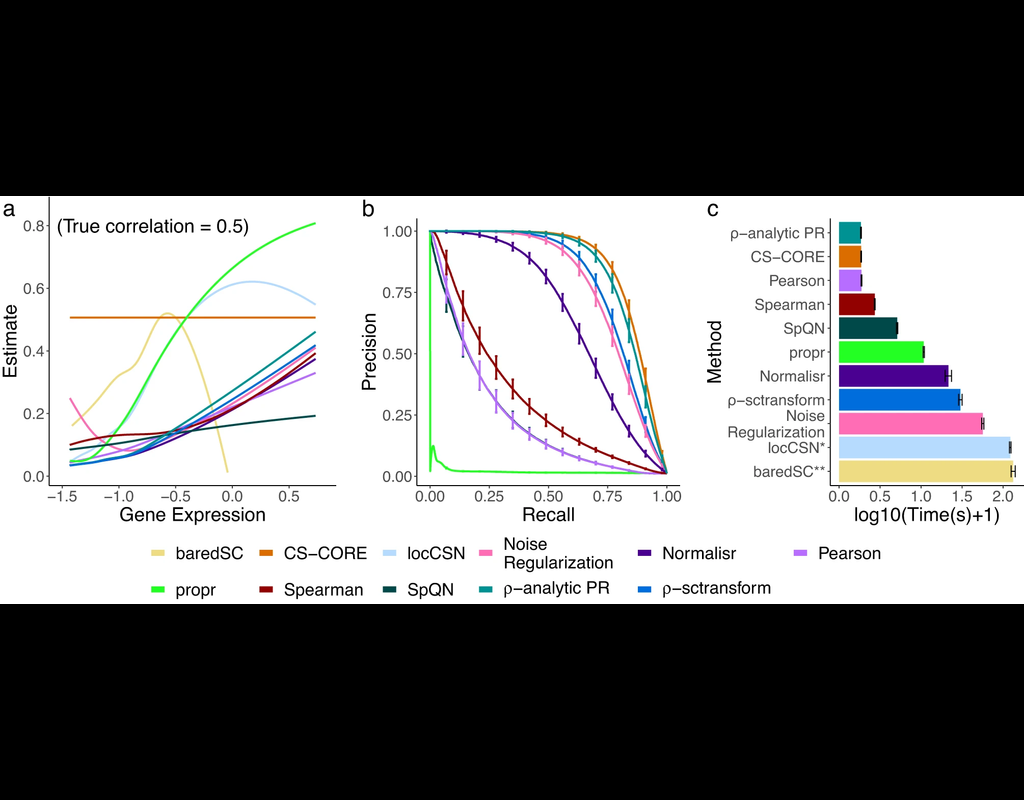
The recent development of single-cell RNA-sequencing (scRNA-seq) technology has enabled us to infer cell-type-specific co-expression networks, enhancing our understanding of cell-type-specific biological functions. However, existing methods proposed for this task still face challenges due to unique characteristics in scRNA-seq data, such as high sequencing depth variations across cells and measurement errors.
CS-CORE (Su, C., Xu, Z., Shan, X. et al., 2023), an R package for cell-type-specific co-expression inference, explicitly models sequencing depth variations and measurement errors in scRNA-seq data.
In this notebook, we will illustrate an example workflow of CS-CORE using a dataset of Peripheral Blood Mononuclear Cells (PBMC) from COVID patients and healthy controls (Wilk et al., 2020). The notebook content is inspired by CS-CORE's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolution.
Here, Runmin Wei (Siyuan He, Shanshan Bai, Emi Sei, Min Hu, Alastair Thompson, Ken Chen, Savitri Krishnamurthy & Nicholas E. Navin) developed a computational method called CellTrek that combines these two datasets to achieve single-cell spatial mapping through coembedding and metric learning approaches. They benchmarked CellTrek using simulation and in situ hybridization datasets, which demonstrated its accuracy and robustness.
They then applied CellTrek to existing mouse brain and kidney datasets and showed that CellTrek can detect topological patterns of different cell types and cell states. They performed single-cell RNA sequencing and spatial transcriptomics experiments on two ductal carcinoma in situ tissues and applied CellTrek to identify tumor subclones that were restricted to different ducts, and specific T-cell states adjacent to the tumor areas.
BioTuring
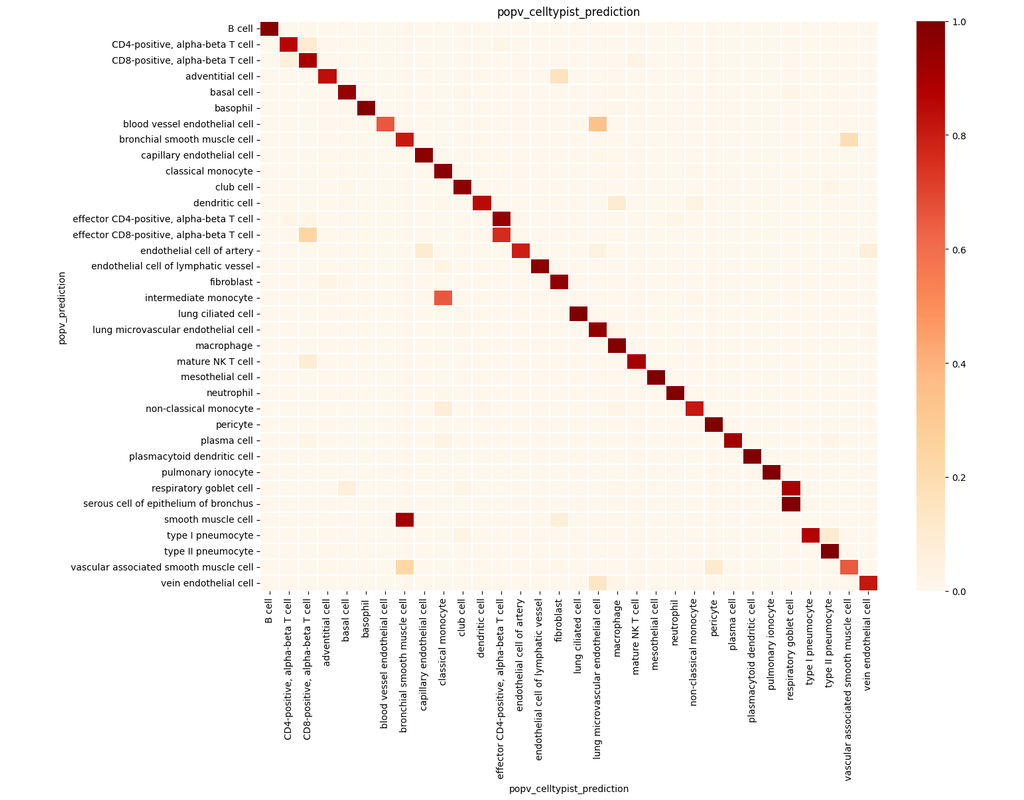
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.
BioTuring
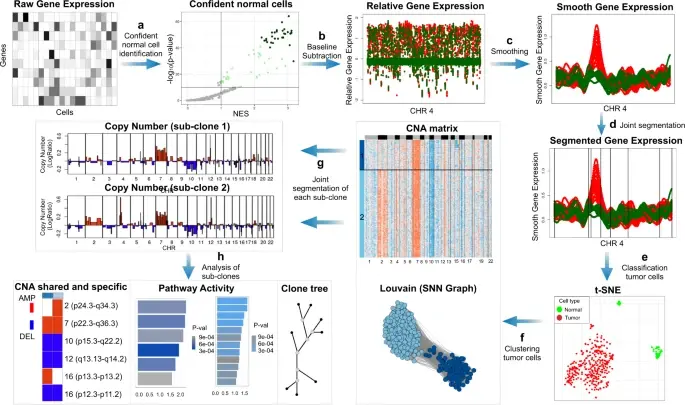
In the realm of cancer research, grasping the intricacies of intratumor heterogeneity and its interplay with the immune system is paramount for deciphering treatment resistance and tumor progression. While single-cell RNA sequencing unveils diverse transcriptional programs, the challenge persists in automatically discerning malignant cells from non-malignant ones within complex datasets featuring varying coverage depths. Thus, there arises a compelling need for an automated solution to this classification conundrum.
SCEVAN (De Falco et al., 2023), a variational algorithm, is designed to autonomously identify the clonal copy number substructure of tumors using single-cell data. It automatically separates malignant cells from non-malignant ones, and subsequently, groups of malignant cells are examined through an optimization-driven joint segmentation process.
Trends
BioTuring
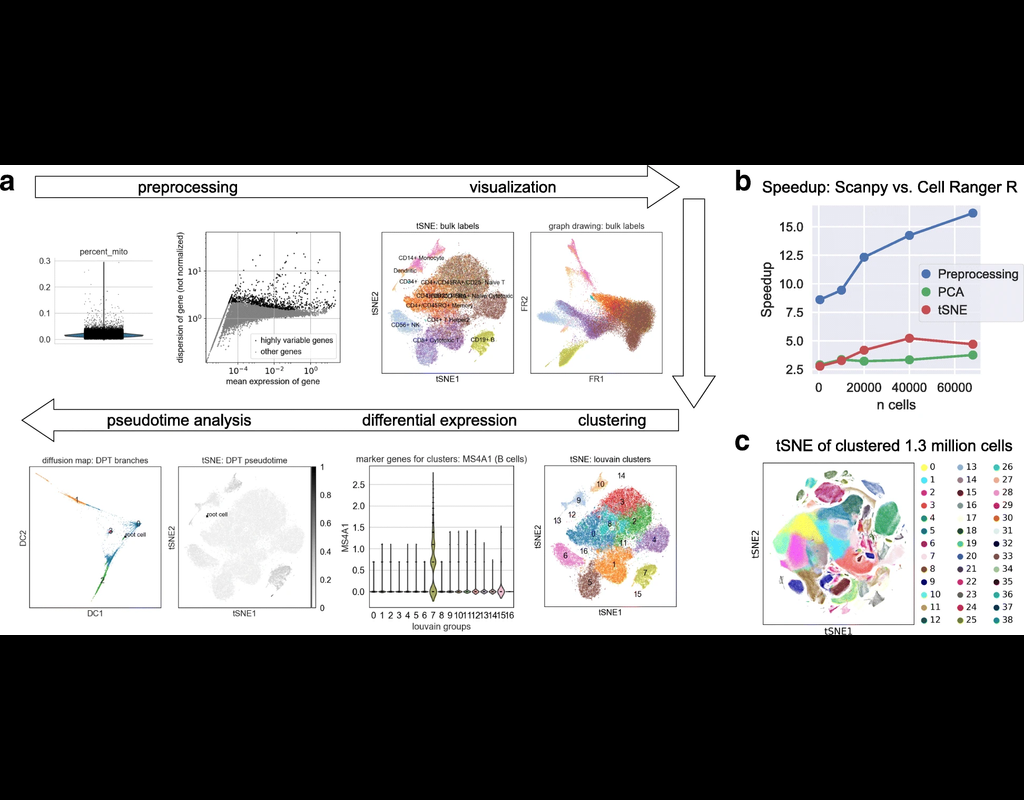
SCANPY integrates the analysis possibilities of established R-based frameworks and provides them in a scalable and modular form.
Specifically, SCANPY provides preprocessing comparable to SEURAT and CELL RANGER, visualization through TSNE, graph-d(More)