




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
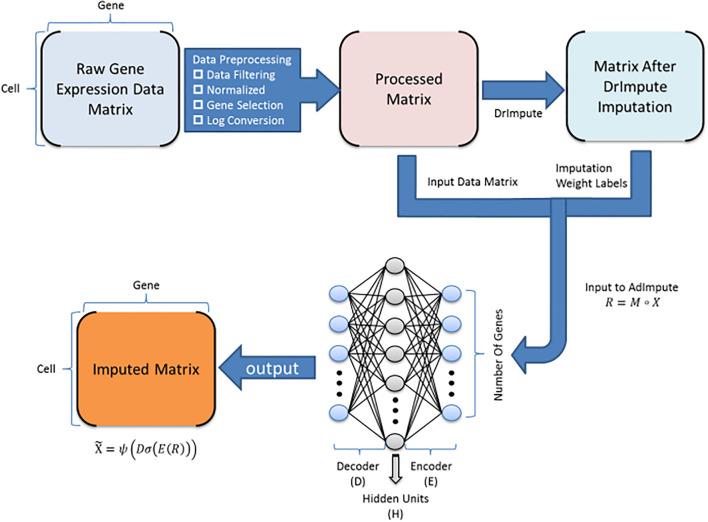
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
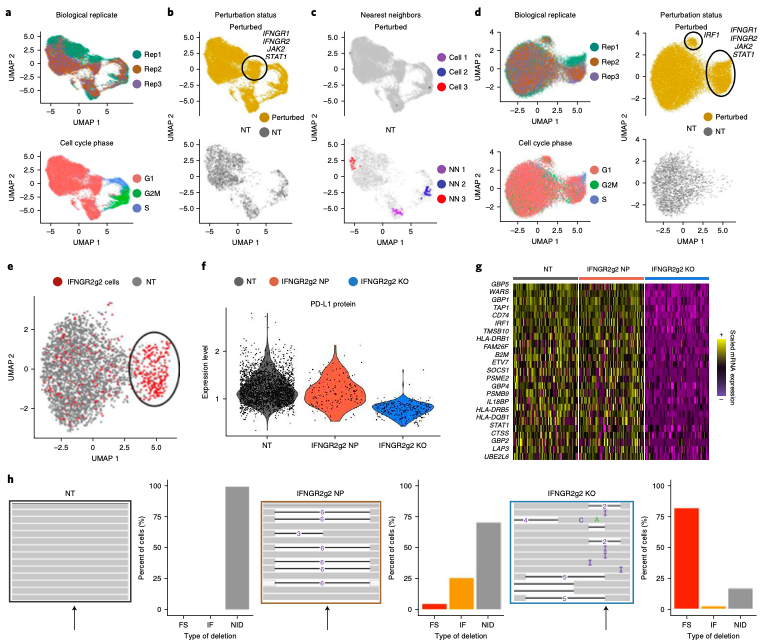
Expanded CRISPR-compatible CITE-seq (ECCITE-seq) which is built upon pooled CRISPR screens, allows to simultaneously measure transcriptomes, surface protein levels, and single-guide RNA (sgRNA) sequences at single-cell resolution. The technique enables multimodal characterization of each perturbation and effect exploration. However, it also encounters heterogeneity and complexity which can cause substantial noise into downstream analyses.
Mixscape (Papalexi, Efthymia, et al., 2021) is a computational framework proposed to substantially improve the signal-to-noise ratio in single-cell perturbation screens by identifying and removing confounding sources of variation.
In this notebooks, we demonstrate Mixscape's features using pertpy - a Python package offering a range of tools for perturbation analysis. The original pipeline of Mixscape implemented in R can be found here.
BioTuring
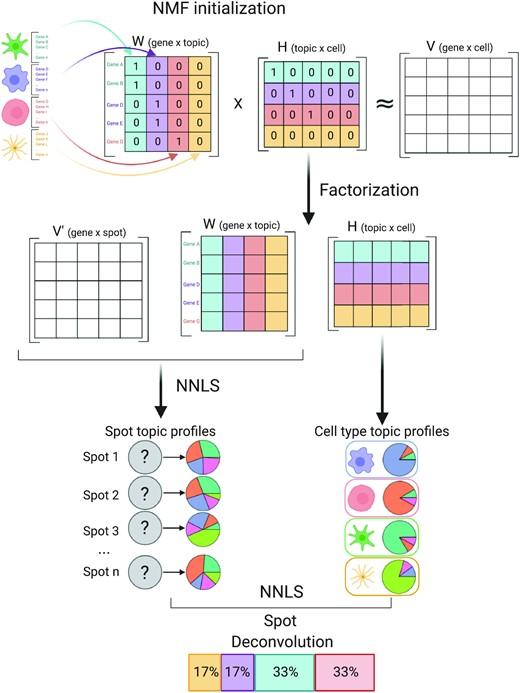
Spatially resolved gene expression profiles are key to understand tissue organization and function. However, spatial transcriptomics (ST) profiling techniques lack single-cell resolution and require a combination with single-cell RNA sequencing (scRNA-seq) information to deconvolute the spatially indexed datasets.
Leveraging the strengths of both data types, we developed SPOTlight, a computational tool that enables the integration of ST with scRNA-seq data to infer the location of cell types and states within a complex tissue. SPOTlight is centered around a seeded non-negative matrix factorization (NMF) regression, initialized using cell-type marker genes and non-negative least squares (NNLS) to subsequently deconvolute ST capture locations (spots).
Simulating varying reference quantities and qualities, we confirmed high prediction accuracy also with shallowly sequenced or small-sized scRNA-seq reference datasets. SPOTlight deconvolution of the mouse brain correctly mapped subtle neuronal cell states of the cortical layers and the defined architecture of the hippocampus. In human pancreatic cancer, we successfully segmented patient sections and further fine-mapped normal and neoplastic cell states.
Trained on an external single-cell pancreatic tumor references, we further charted the localization of clinical-relevant and tumor-specific immune cell states, an illustrative example of its flexible application spectrum and future potential in digital pathology.
BioTuring
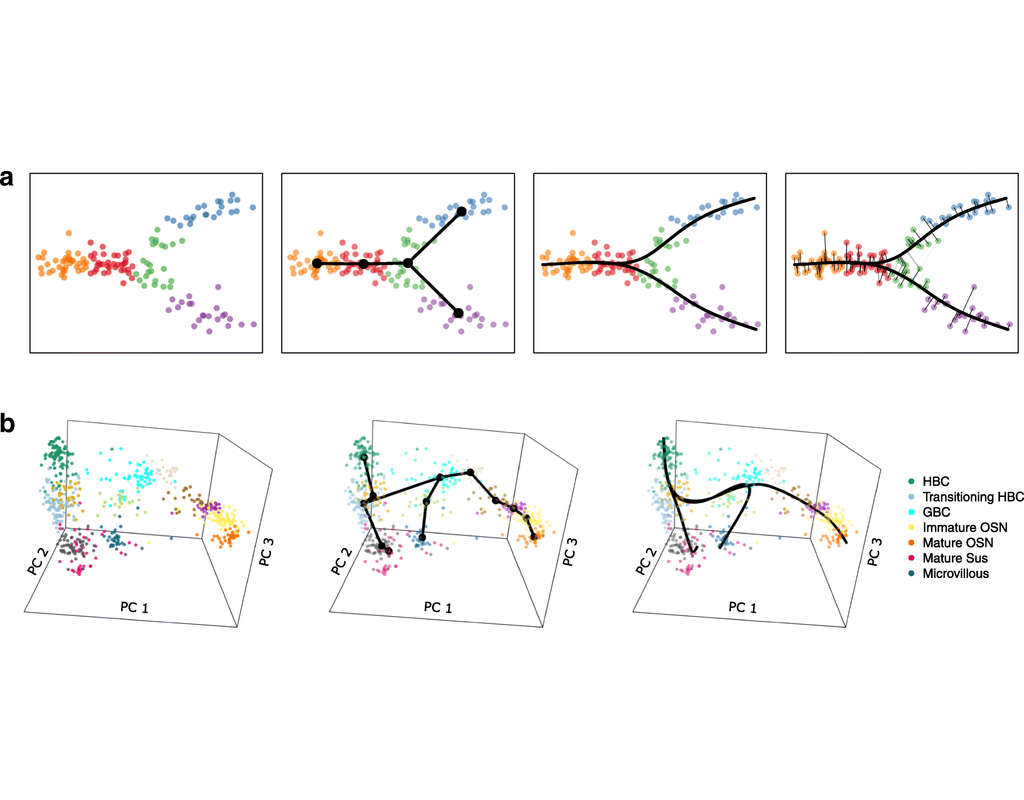
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.