




Notebooks

Categories



Cells
Premium

BioTuring
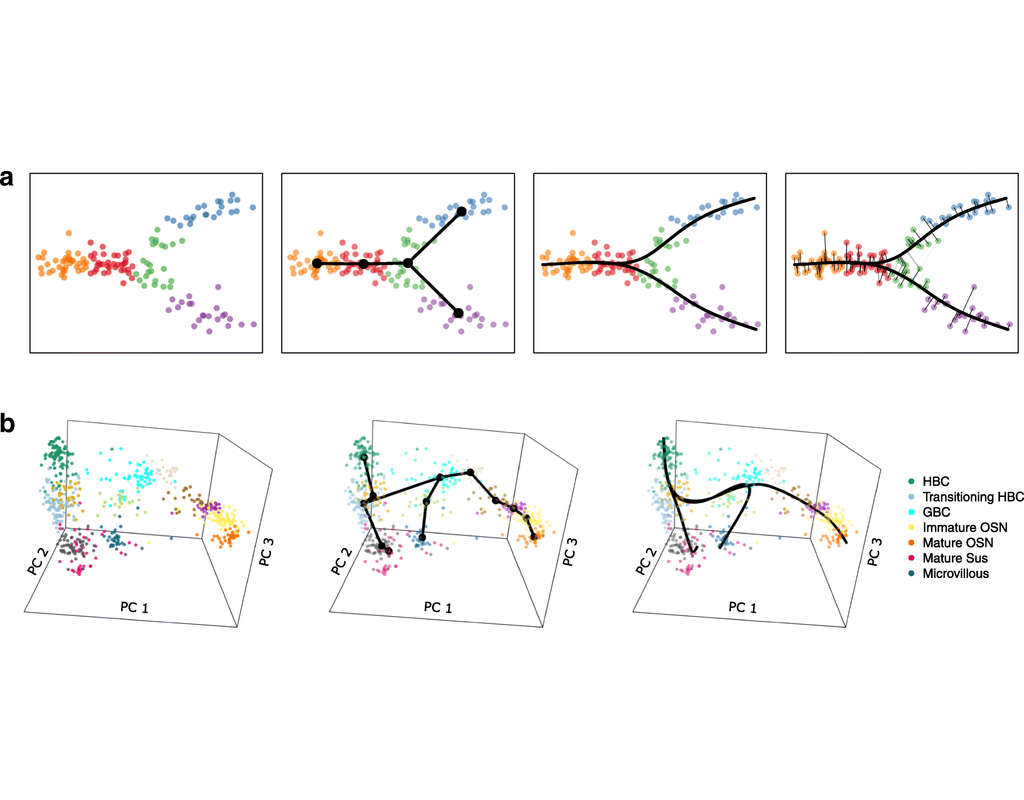
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.
BioTuring
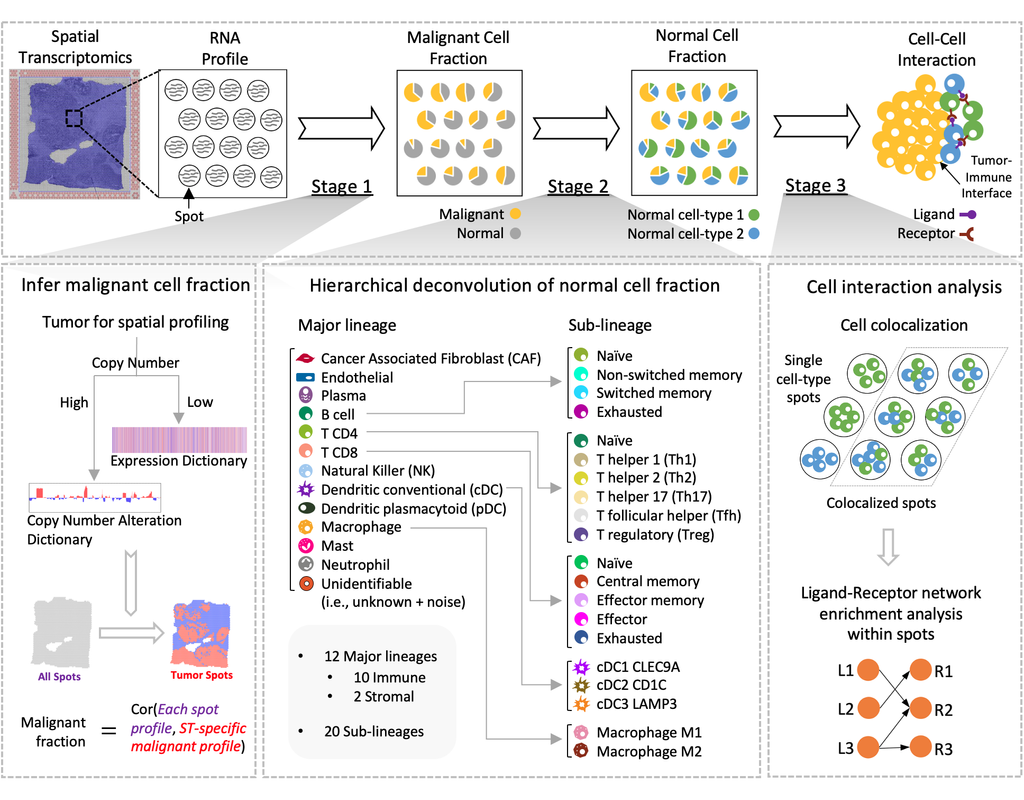
Spatial transcriptomics (ST) technology has allowed to capture of topographical gene expression profiling of tumor tissues, but single-cell resolution is potentially lost. Identifying cell identities in ST datasets from tumors or other samples remains challenging for existing cell-type deconvolution methods.
Spatial Cellular Estimator for Tumors (SpaCET) is an R package for analyzing cancer ST datasets to estimate cell lineages and intercellular interactions in the tumor microenvironment. Generally, SpaCET infers the malignant cell fraction through a gene pattern dictionary, then calibrates local cell densities and determines immune and stromal cell lineage fractions using a constrained regression model. Finally, the method can reveal putative cell-cell interactions in the tumor microenvironment.
In this notebook, we will illustrate an example workflow for cell type deconvolution and interaction analysis on breast cancer ST data from 10X Visium. The notebook is inspired by SpaCET's vignettes and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
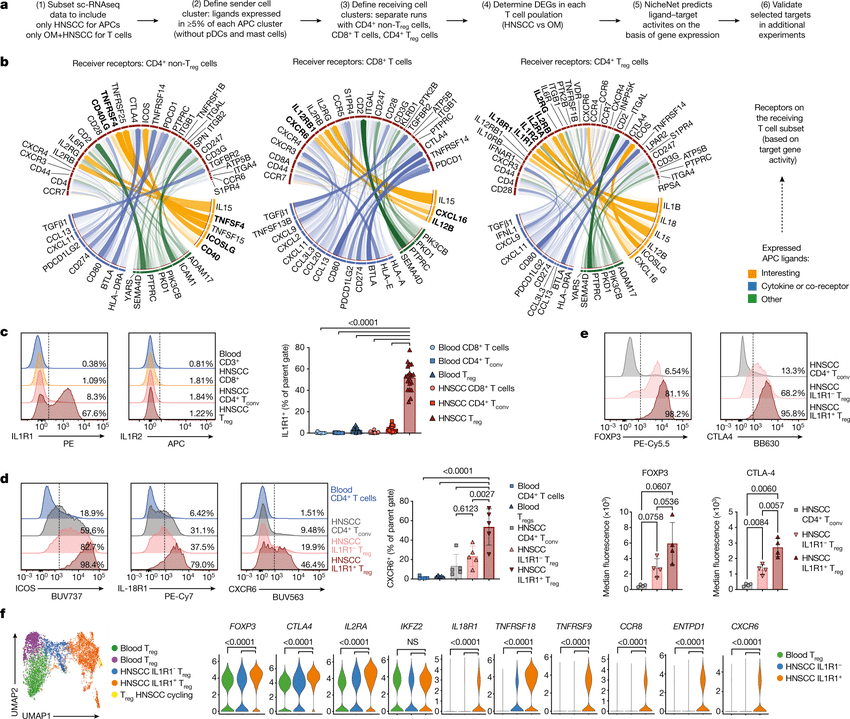
Computational methods that model how the gene expression of a cell is influenced by interacting cells are lacking.
We present NicheNet, a method that predicts ligand–target links between interacting cells by combining their expression data with prior knowledge of signaling and gene regulatory networks.
We applied NicheNet to the tumor and immune cell microenvironment data and demonstrated that NicheNet can infer active ligands and their gene regulatory effects on interacting cells.
Trends
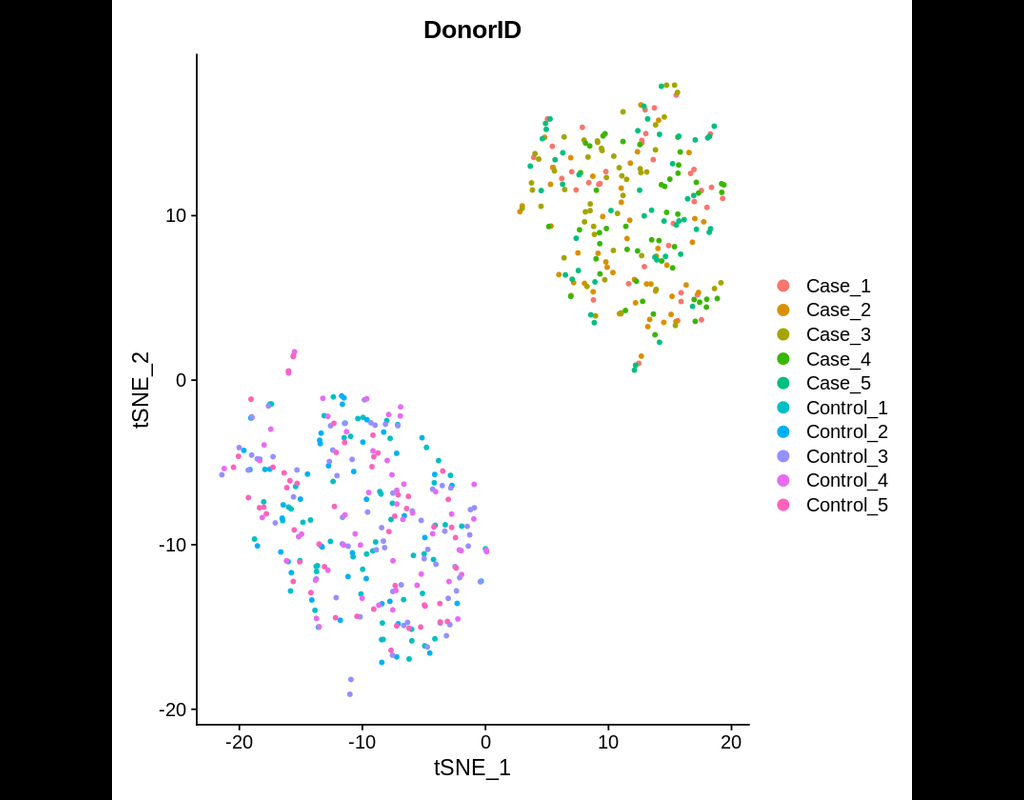
BioTuring
Power analyses are considered important factors in designing high-quality experiments. However, such analyses remain a challenge in single-cell RNA-seq studies due to the presence of hierarchical structure within the data (Zimmerman et al., 2021). As(More)